Technisches Konzept¶
Graphenmodell¶
Zusammenhänge zwischen Entitäten (Person, Ort, Zeit, Idee) werden im Cosmotool zukünftig in Form eines gewichteten Graphen modelliert. Entitäten werden dabei durch Knoten, Bezüge zwischen den Entitäten durch Kanten repräsentiert. Aufgrund der typischen Unsicherheit erkannter Bezüge – insbesondere im Fall der Identifizierung durch automatische Verfahren – wird eine errechnete Konfidenz in Form des Kantengewichts abgebildet.
Erste Arbeiten der Implementierung wurden hierzu bereits durchgeführt. Wissenschaftlich spannend ist hierbei insbesondere die Integration von Konfidenzwerten (Kantengewichte), sowie die Transparenz deren Herleitung.
Qualitative Verfahren¶
Der Erfolg quantitativer Verfahren für die Erkennung und Einschätzung biographischer Ereignisse und insbesondere der Erkennung und Zuweisung von ideengeschichtlicher Aspekte ist insbesondere von der gezielten Steuerbarkeit durch qualifizierte Experten abhängig.
Abbildung 8 zeigt die drei im Cosmotool vorgesehenen Stellen der qualitativen Interaktion: Neben manueller Korrekturmöglichkeiten an biographischen Profilen soll insbesondere die Veränderung von Heuristiken und Modellen, also des in semi-automatischen Verfahren angewendeten Domänenwissens ermöglicht werden. Zudem erhalten Anwender des Systems Möglichkeiten die Zusammenstellung betrachteter Datenbasen zu verändern. Dies bedeutet die Eintragung, Veränderung oder Löschung von Einträgen in der dedizierten Collection Registry bzw. auch die Selektion relevanter Quellen zum Anfragezeitpunkt.
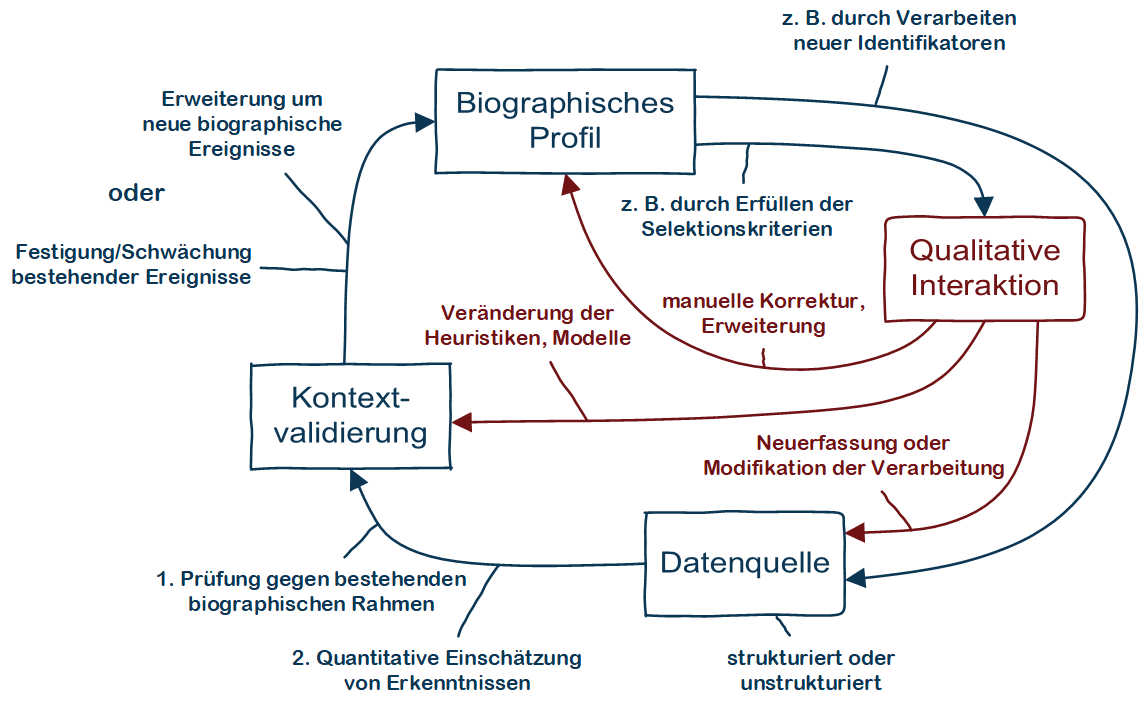
Abbildung 8 Zusammenwirken qualitativer und quantitativer Verfahren
Wortfelder¶
Als erster weiterführender, methodischer Schritt zur Klassifikation und Beschreibung von Personengruppen wurde eine Möglichkeit zur Registrierung definitorischer Wortfelder [Go84] implementiert. Als Wortfeld wird eine Menge von Begriffen verstanden, die in einem Bedeutungszusammenhang stehen.
Für den Einsatz im Cosmotool ist vorgesehen, dass Domänenexperten global sichtbare, übrige Anwender individuell verwendbare Wortfelder definieren können, die eine Selektion und Klassifikation von Personen erlaubt. Um im Beispiel des qualitativ erarbeiteten Pietistennetzwerks durch quantitative Unterstützung weitere Personen zuweisen zu können, erarbeitet das IEG derzeit klassifizierende Wortfelder für religiöse Gruppen. Neben der manuellen, direkten Erfassung von Wortfeldern ist zudem die Errechnung solcher auf Basis definitorischer Texte vorgesehen.
Datenföderationsarchitektur¶
Vergleichbar mit der Generischen Suche [1] von DARIAH-DE ist auch das Cosmotool ein integratives Werkzeug, welches auf der Basis von:
- verschiedenen Dokumentkollektionen (biographische Texte und Daten) und
- heterogenen Datenmodelle (unterschiedliche Schemata, unstrukturierte Daten)
- integrative Sichten auf biographische Profile von Personen erreichen möchte.
War der Prototyp des Cosmotools in seiner initialen Entwicklung in den ersten Phasen (2011-2016) von DARIAH-DE noch als autonome Komponente implementiert worden, um in möglichst kurzer Zeit erste vorzeigbare Ergebnisse zu generieren, so hatte sich bereits im Verlauf der Entwicklungen gezeigt, dass die synergetische Entwicklung der Werkzeuge sowohl für die Komponenten der DARIAH-DE Datenföderationsarchitektur (DFA, Abbildung 9) wesentliche Vorteile sowohl für die DFA, als auch die Umsetzung des Cosmotools selbst.
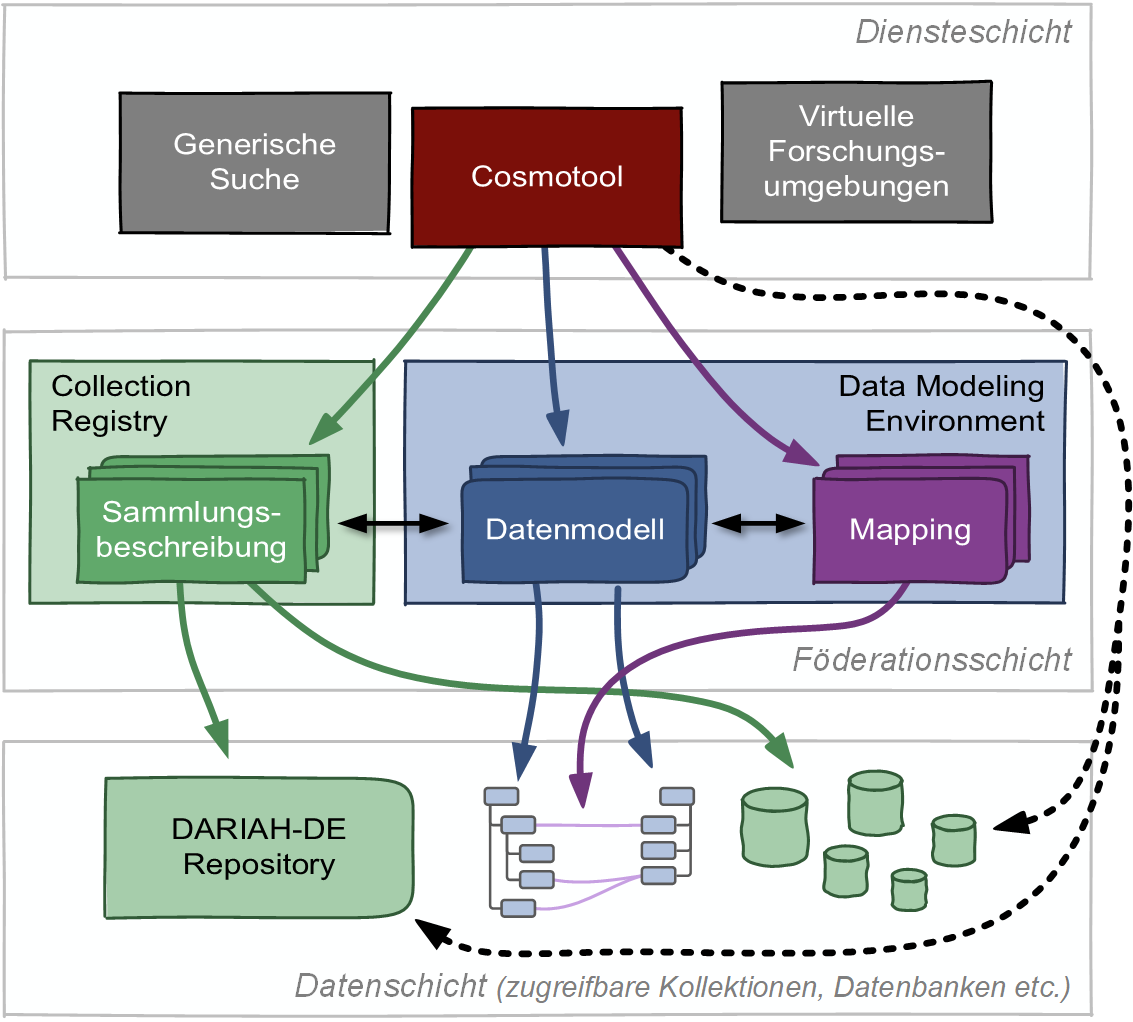
Abbildung 9 Zusammenwirken qualitativer und quantitativer Verfahren
So werden die dem Cosmotool zu Grunde liegenden Datenquellen im Rahmen einer dedizierten Instanz der Collection Registry verwaltet. Schemata und Regeln zur Verarbeitung biographischer Daten werden in der Schema Registry definiert.
Das semantische Cluster Biographien (nach Definition in [Gr16a], Abbildung 10), welches mit Hilfe der Komponenten der DFA entwickelt wird. Datenmodelle (hier M1...M4) werden durch Mappings assoziiert.
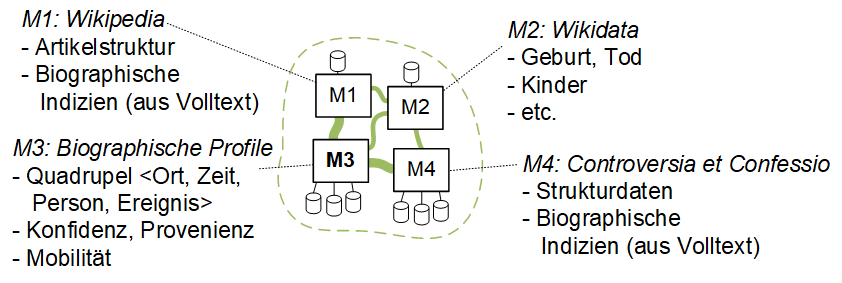
Abbildung 10 Semantisches Cluster Biographien (vereinfacht)
Der Bildschirmausschnitt in Abbildung 11 zeigt einen Ausschnitt der Modellierung von Personeneinträgen aus Wikipedia. Hier wurde z. B. spezifiziert, wie die in den Artikel integrierten strukturierten Daten (im Ausschnitt) zu entnehmen sind, Textstellen mit Hilfe von NLP zu verarbeiten sind und gefundene biographische Evidenz auf die biographischen Profile zu mappen sind. Für Details verweisen wir an dieser Stelle auf [Gr16c].
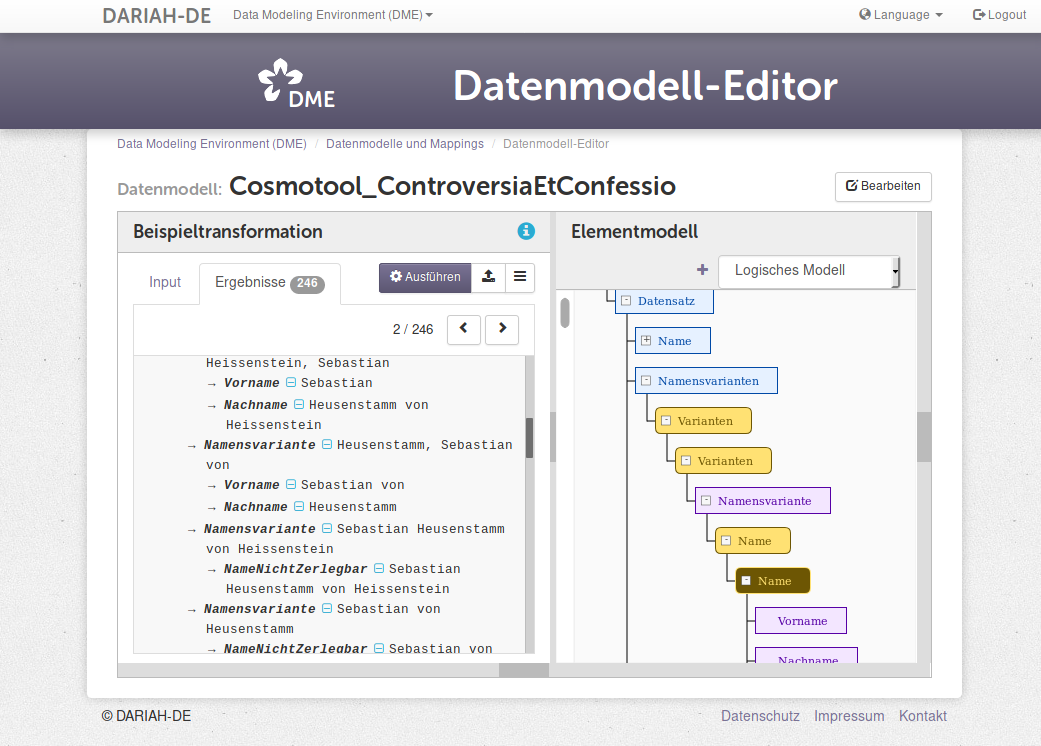
Abbildung 11 Modellierung im Data Modeling Environment (DME)
| [1] | unter https://search.de.dariah.eu |